A question I've been asking recently is: in a world of (mostly) free SaaS CI/CD services (like GitHub actions and GitLab CI), why would I go through the effort of hosting my own?
For the last six or so years, I've been hosting a Concourse CI server and two worker nodes (all hosted in Linode). Recently, I've expanded this to an additional three on-prem workers for performance reasons, and the ability to interact with things on my local network without using tailscale or something. I have some CD workflows in Concourse, but services that run in my kubernetes cluster are managed via Argo CD. I've mentioned Argo CD in another post, so I won't discuss that here.
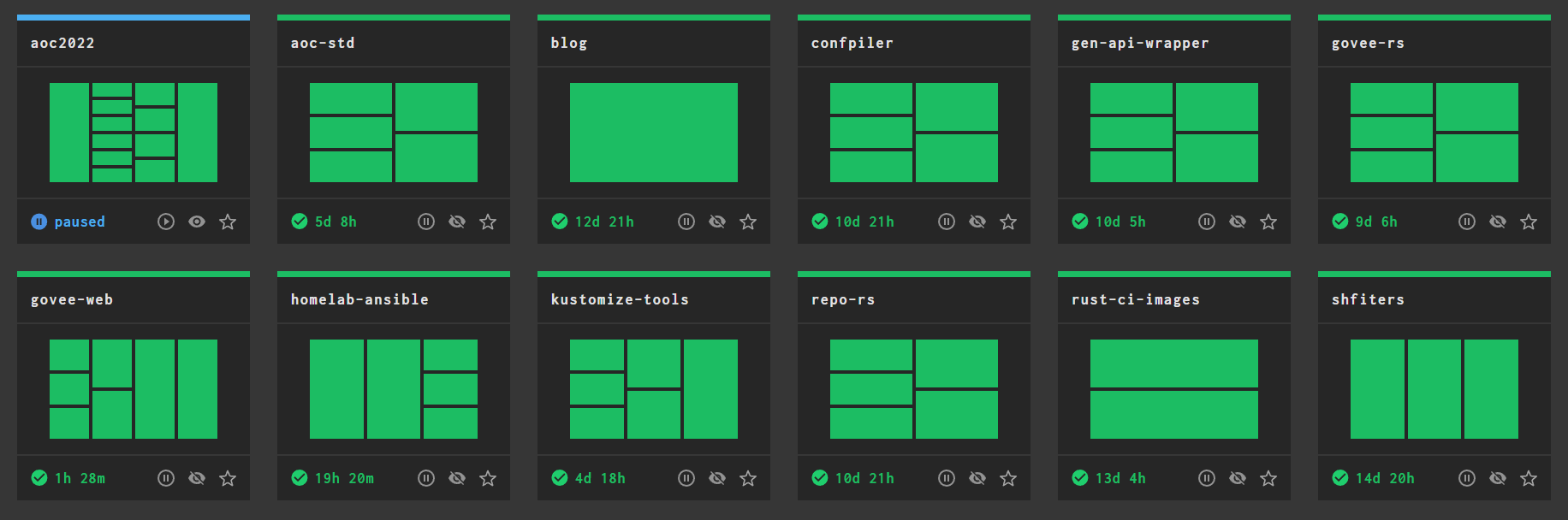
my current Concourse dashboard
In addition to Concourse and Argo CD, I've used the following (in alphabetical order):
There is no perfect tool that fits all workflows. I firmly believe Jenkins is in the state it's in because it tried to do everything well and ended up doing everything just-okay, but that comes from the bias of the teams wanting to replace Jenkins at the last three places I've worked without finding an alternative that was worth the effort of switching.
GitHub actions is great for simple projects, but potentially slow without self-hosted runners for performance and the potential to more easily cache portions of a build. Other tools (including Concourse) have their own problems.
Why I initially picked Concourse
At the time, I chose concourse because of its focus on pipelines, isolation of
build steps to containers and its philosophy regarding shared state and
reproducibility. The former two things are things that are commonplace these
days, and the latter is something I've come to view as somewhat of a pain, at
least for the "home" user, although I think having to work around some of
those limitations has forced me to come up with better workflows. For those
unfamiliar with what I'm talking about, Concourse has pipelines that consist
of jobs and those jobs have steps. Unlike some other build tools (like
Jenkins), Concourse does not have a built-in method of propagating artifacts
from one job to another, meaning that any artifacts need to be pushed/uploaded
to external systems (like docker hub, pypi, deb package repos, etc.) if you
intend to consume them in subsequent jobs. There is a way to pass
state/artifacts between the steps of a job, but unless you have pipelines
that consist of single jobs, you'll still need some external system to store
artifacts. The upside to this is that pipelines are independent of the
particular Concourse server that's executing them, meaning that if you lost the
server or had to migrate to a new one, builds would not fail because the server
lacked some artifact you needed to run a pipeline. It also means that you're
much less likely to have a pipeline fail because of some ephemeral state you
depend on: everything is explicit.
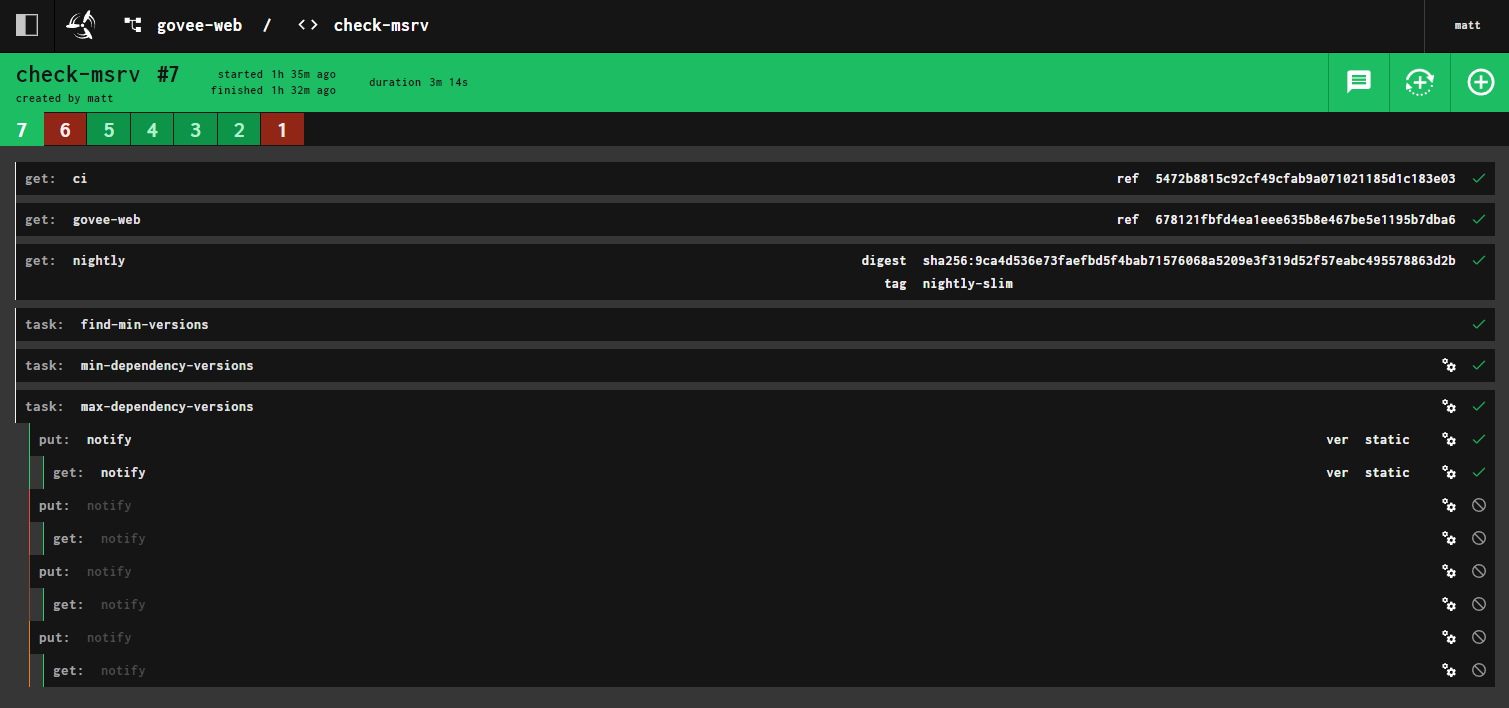
an example of a particular job in the pipeline
It's not without its flaws, however. Concourse uses resources that can be git
repositories, docker hub images, github releases, etc. While you can gate
downstream jobs on a resource passing one or more upstream jobs. However
Concourse lacks conditional steps, which means there's no easy way to skip the
remainder of a pipeline without failing the current job to prevent the
propagation. This limitation makes the following very difficult to accomplish:
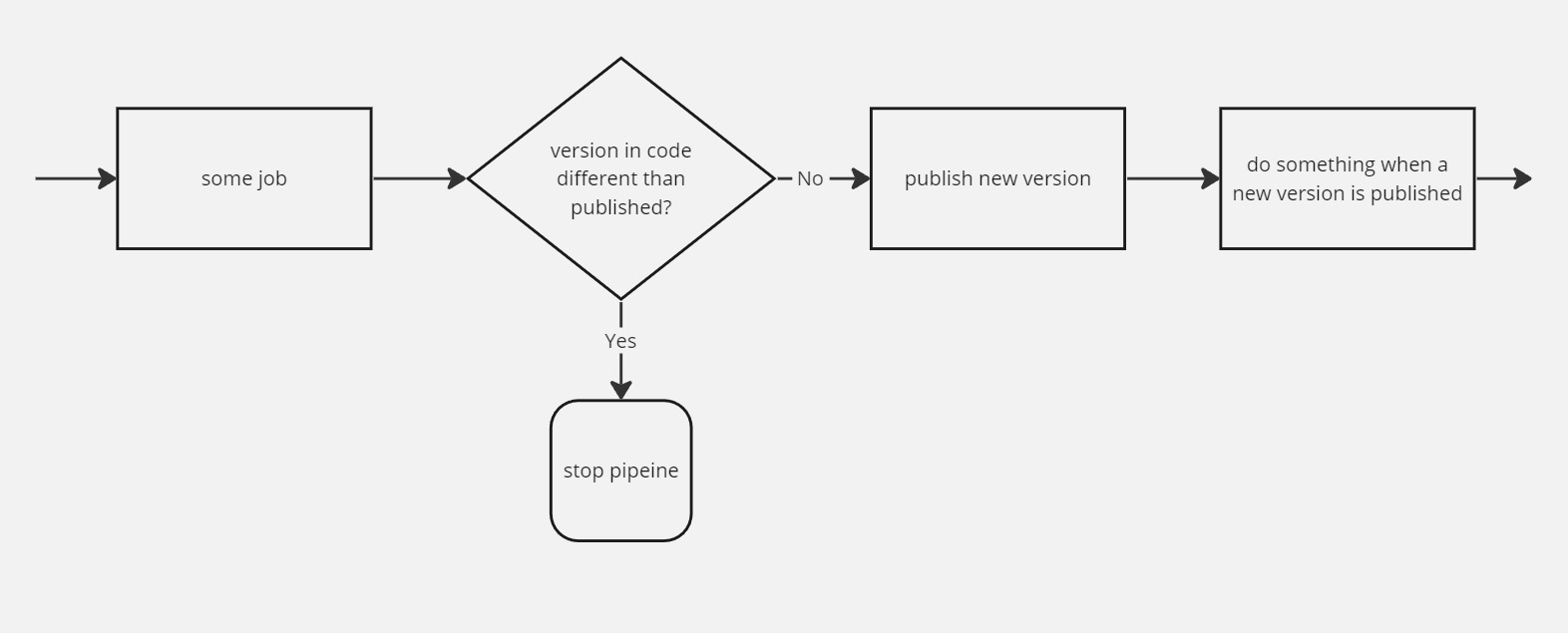
hard to do without a hack using an across step
There's an outstanding RFC and several issues regarding this (example), though still no satisfying resolution outside of a convoluted workaround.
Support for PR builds is also a little lacking, and the resources maintained by the Concourse org and the community can be hit-or-miss in terms of having the functionality you want/need.
What keeps me putting up with Concourse
Despite those (and other) annoyances, the thing that keeps me from switching is that Concourse pipelines are not tied to a particular repository but rather to a set of resources. This is different than most tools (GoCD being the exception) where the triggers for a particular build are usually limited to changes to one repository (GitHub actions, for instance). By having the pipeline definition declare the resources being consumed, it possible to have a pipeline that is triggered by changes to one or more different repositories, docker registries, releases, etc.
An example of where this comes in handy is my pipeline for benchmarking various Advent of Code solutions from my friend group against one another.
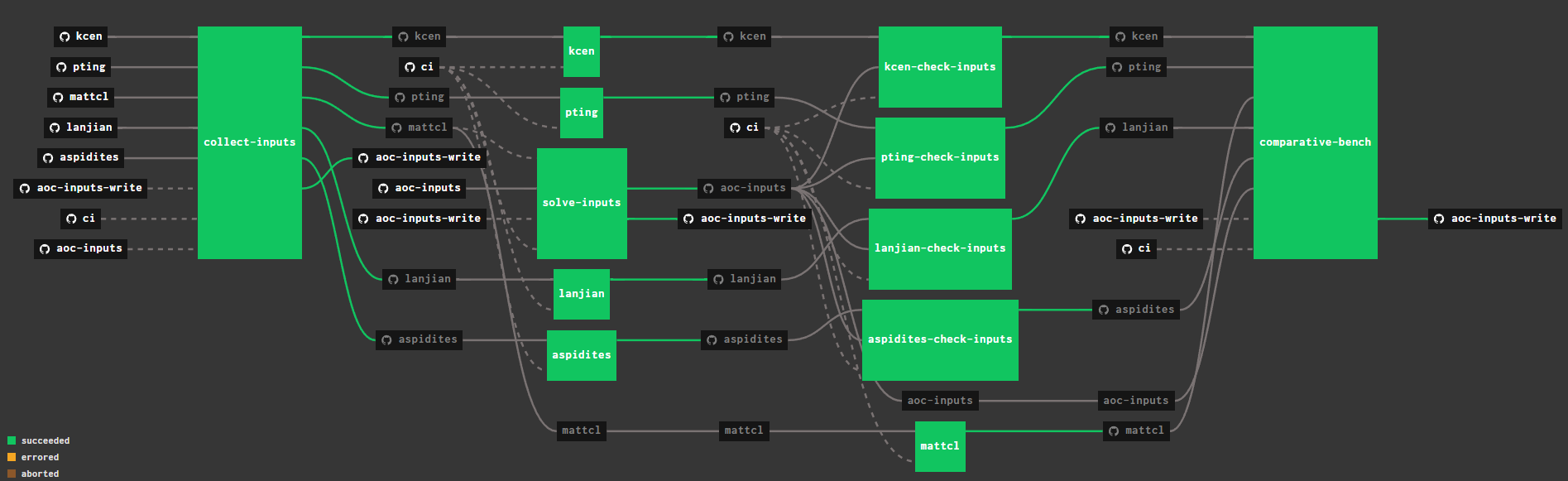
the 2022 AoC pipeline
The pipeline can be triggered by a change to any of the repos at the start (left) of the pipeline while using code from every repo in the benchmarking job. While this may have been possible to do in some of the other tools, the configuration would not have been as straightforward, and would involve some hacking around to get the tool do do what I wanted.
Another example of it being useful to "watch" multiple resources is this
pipeline for govee-rs, my Govee light control library.
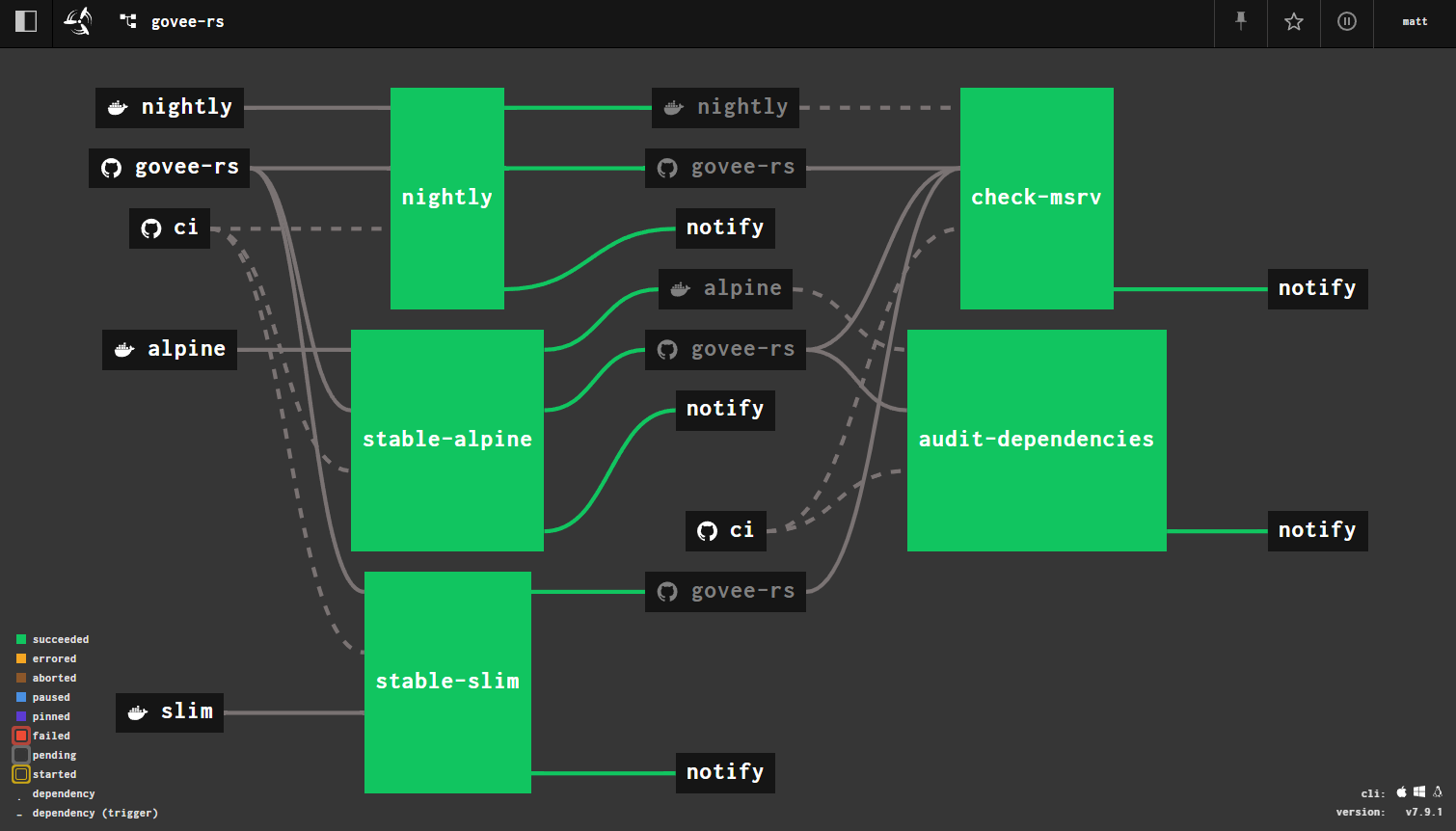
a rust library pipeline
Here I watch the govee-rs repo for
changes, like you would normally do in other tools. However, unlike in other
tools, I also watch for changes to the rust docker images, including the nightly
image. This has the effect of also triggering a build when a new version of
one of those images is pushed to Docker Hub. This could be accomplished in
another tool by using a cron trigger to automatically build at a particular
interval, with the build job pulling the "latest" image or something more
intelligent. Here I just declare those resources as triggers.
You may have noticed that there's a ci repo specified for this pipeline.
Because the pipeline is not tied to a particular repository, it allows for
defining the actual pipeline, jobs, and tasks separately. Here I have a
repo that contains general pipelines and
tasks for testing and, in some cases, shipping rust projects (a TODO is working
on auto-publishes to crates.io or my private cargo registry). Individual
projects simply override vars pertaining to the repo source and such when
creating a new pipeline.
Here's an example of a variation on the "core" pipeline that publishes a docker image containing the executable of a rust bin (in this case a simple tool for working with kustomization files).
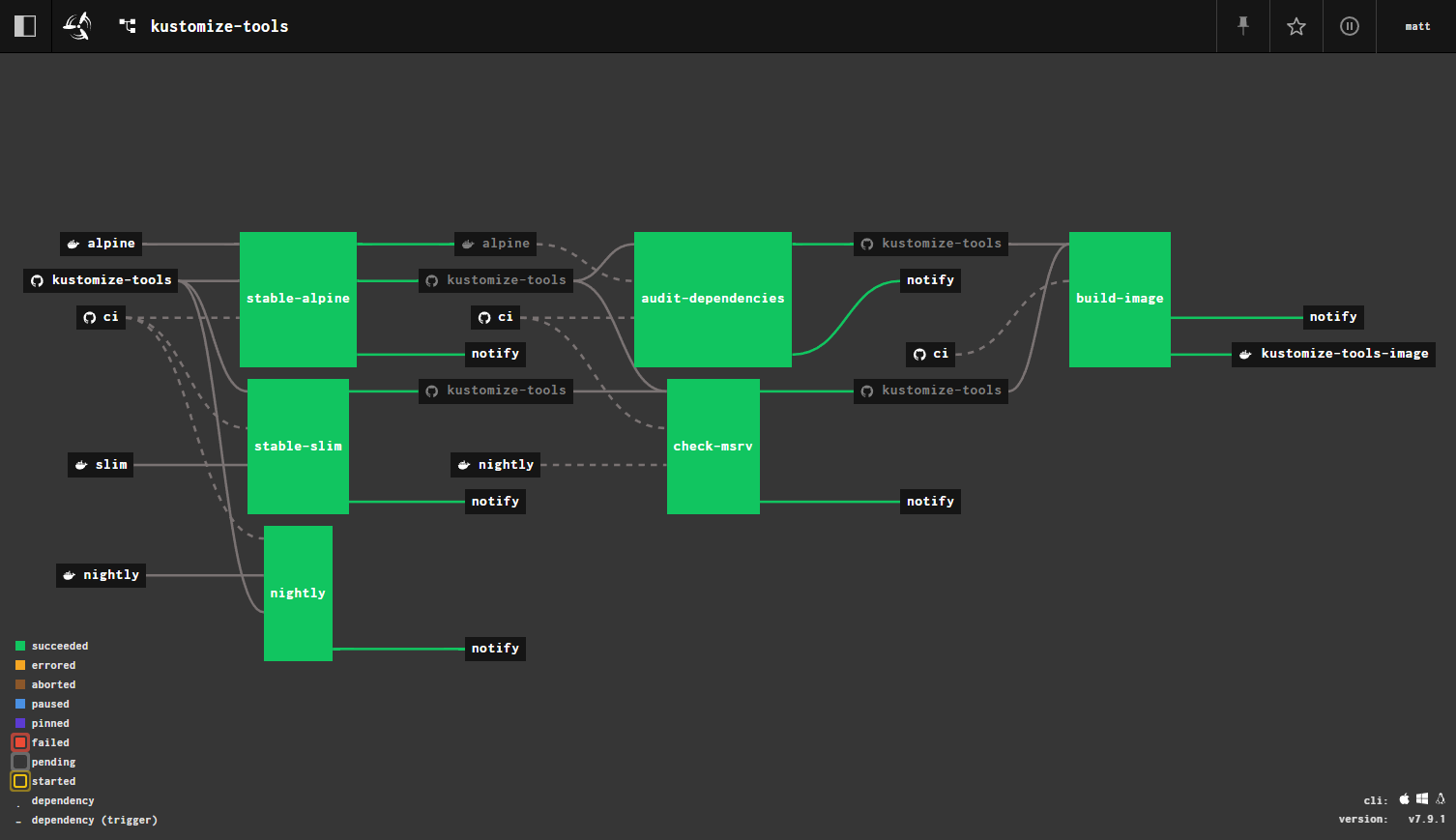
a rust bin pipeline with a docker image
It has the same set of steps initially that the lib pipeline has (sourced from
the ci repo, while also publishing a docker image from a revision that's
passed the previous steps. The image is automatically tagged with the bin
version (though I had to have a workaround for when that version is already
published, i.e. my earlier complaint about conditionals).
Another example is this web service pipeline for my govee-web service.
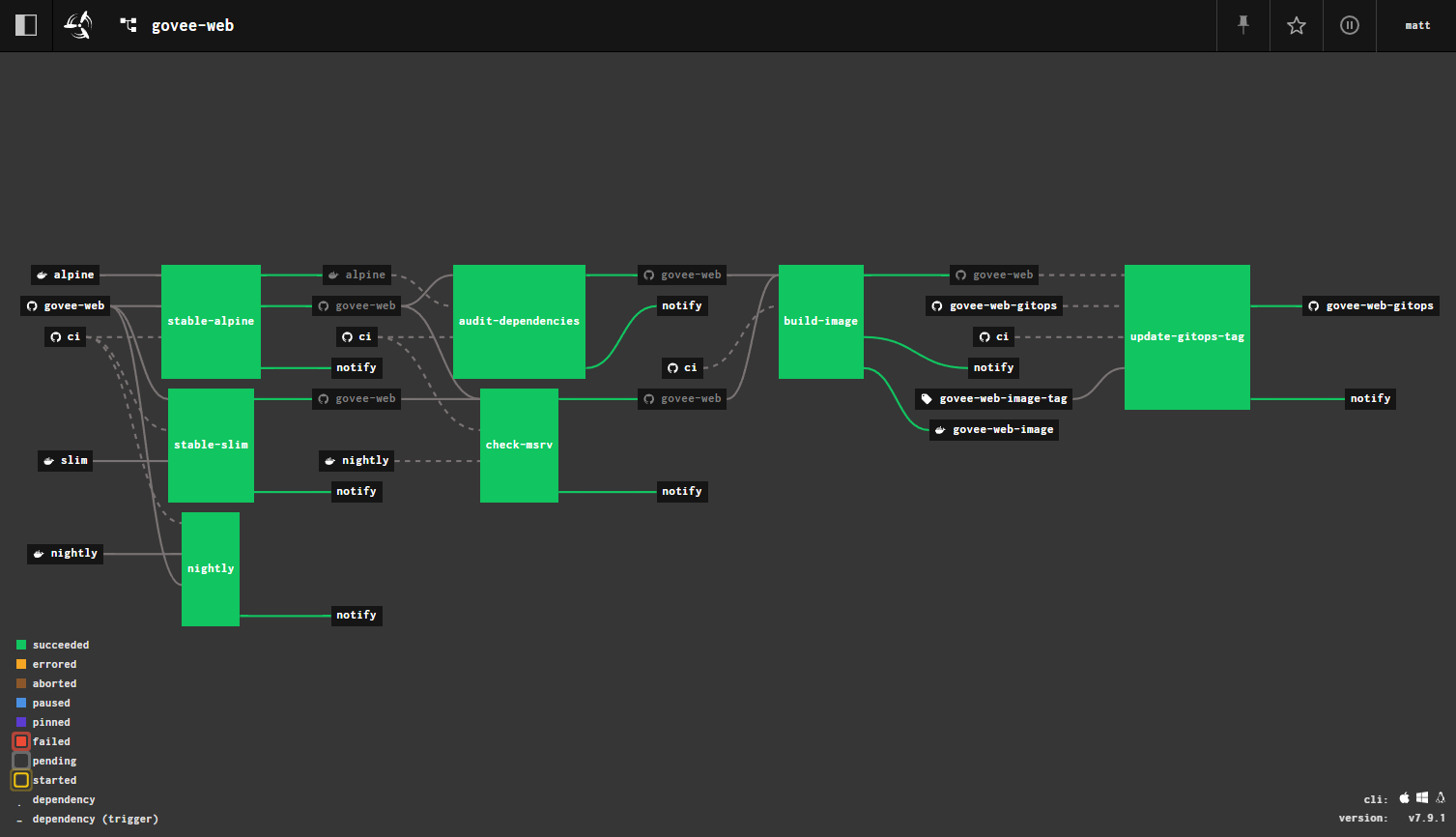
a rust web service pipeline
This is basically the same pipeline layout as the previous one, but with the additional step of then watching for new tags to appear in Docker Hub and updating the gitops repo to set the container version for the deployment with the new tag. When that repo is updated, my Argo CD server (watching that repo) automatically deploys the new version of the service into my kubernetes cluster.
Unlike for the library pipeline, failing the nightly rust job for a service
pipeline does not fail the whole pipline, as nightly is just used for early
warnings of incompatibility in these cases.
Doing the work upfront to make generalized pipelines has drastically sped up development on a few of my other projects, and provides me a way with quickly getting a "standard" CI workflow in place for new projects.
My hope for the future
Concourse is powerful and can be made to do most things other tools can do, but there are often situations where the abstractions make it difficult and/or inefficient to model "simple" pipeline behaviors (like control-flow). I'd like to see some traction on the RFC for a conditional step, but that issue is several years old at this point.
What would probably benefit Concourse (and the community as a whole) would be a modern competitor that also treats repos as simply another pipeline resource instead of the trigger for the pipeline itself, as this would offer an alternative while likely driving more rapid change with regard to the Concourse road map.
In the meantime, I plan on refining my general rust ci pipelines further, and will likely write a simple yaml merging tool to DRY-up some of the pipeline duplication in my ci repo.
I've also been tossing around the idea of writing that Concourse replacement myself, but I don't think I have time for that, just yet...