Every year, I aim to complete Advent of Code in the shortest overall runtime while being able to solve any given input. This year I did it in both rust and python. These are some observations/musings.
TL:DR
This year, my total non-cold-start rust runtime was roughly 25 milliseconds, while my python runtime was about 1.7 seconds. These times were measured on a machine with an i5-12600k, with 128 GB of RAM, and inputs were read off of a Samsung 980 Pro NVMe SSD. The OS is Ubuntu server 22.04. Benchmarks include file parsing but not time to read the files from disk. The python benchmarks additionally do not include the time to start the interpreter (I did also measure cold-start times separately, but more on that later). I've included summaries of the benchmark results below.
These are by no means the fastest times I've seen, though my rust runtime is within the ballpark of the fastest rust time I've seen so far (10 ms). Of the python solutions I've managed to directly compare against, my overall runtime is as good or better. Individual days are mostly in the ballpark of other solutions.
Rust
+-------------------------------------------------------------+
| Problem Time (ms) % Total Time |
+=============================================================+
| 001 trebuchet 0.06723 0.270 |
| 002 cube conundrum 0.01480 0.059 |
| 003 gear ratios 0.08415 0.338 |
| 004 scratchcards 0.03774 0.151 |
| 005 you give a seed a fertilizer 0.01162 0.047 |
| 006 wait for it 0.00027 0.001 |
| 007 camel cards 0.10829 0.435 |
| 008 haunted wasteland 0.32761 1.315 |
| 009 mirage maintenance 0.04608 0.185 |
| 010 pipe maze 0.22459 0.901 |
| 011 cosmic expansion 0.01197 0.048 |
| 012 hot springs 0.56546 2.269 |
| 013 point of incidence 0.03004 0.121 |
| 014 parabolic reflector dish 2.48077 9.956 |
| 015 lens library 0.13207 0.530 |
| 016 the floor will be lava 2.86935 11.516 |
| 017 clumsy crucible 7.12009 28.576 |
| 018 lavaduct lagoon 0.02418 0.097 |
| 019 aplenty 0.11363 0.456 |
| 020 pulse propagation 1.66637 6.688 |
| 021 step counter 0.60420 2.425 |
| 022 sand slabs 0.68756 2.759 |
| 023 a long walk 4.09091 16.419 |
| 024 never tell me the odds 0.25839 1.037 |
| 025 snowverload 3.33897 13.401 |
| Total 24.91636 100.000 |
+-------------------------------------------------------------+
Python
------ benchmark: 25 tests -------
Name (time in ms) Mean StdDev
----------------------------------
test_day01 1.7859 0.0349
test_day02 0.6200 0.0293
test_day03 2.7599 0.0839
test_day04 0.6197 0.0262
test_day05 1.0391 0.0323
test_day06 0.0051 0.0003
test_day07 2.5412 0.4279
test_day08 6.7066 0.6922
test_day09 1.3349 0.0495
test_day10 11.6985 0.3411
test_day11 0.5428 0.0188
test_day12 78.0007 10.9906
test_day13 1.8996 0.0626
test_day14 157.3659 2.7023
test_day15 6.6442 0.1941
test_day16 347.0442 34.7542
test_day17 286.8772 2.0432
test_day18 0.6517 0.0205
test_day19 2.3693 1.0639
test_day20 112.3589 2.0881
test_day21 173.5629 8.6991
test_day22 71.1298 8.4224
test_day23 330.0346 9.6357
test_day24 31.0174 0.6720
test_day25 54.0391 20.6532
----------------------------------
# combined
---------- benchmark: 1 tests ----------
Name (time in s) Mean StdDev
----------------------------------------
test_combined_runtime 1.6918 0.0361
----------------------------------------
Quirks and details
As always, the solutions I've come up with should solve any valid (official) input. I've noticed some solutions out there fail to solve certain inputs, including many of the geometric solutions for day 21. My testing caught that my rust solutions needed to use larger integer types for some days on some inputs.
Solutions are not necessarily required to solve the example inputs for situations where the example has no part 2 solution or lacks the special property that makes the problem solvable.
A note on external dependencies
For python, I attempted to limit myself to vanilla python 3.12 with no external
dependencies. The rationale for this is that solving a problem with a compiled
external library like numpy is no longer really testing python performance if
most of the heavy lifting is being done by an external library written in a
different language. It would be relatively easy to use pyO3 to expose my rust
solutions to python and "solve" it in python, but those benchmarks would be
meaningless and not in the "spirit" of this exercise.
I mostly succeeded at this goal. Day 24 and 25 in python use numpysympy and networkx respectively, but all other days have no external
dependencies. The reason why 24 and 25 use external packages is down to pure
laziness, in that after I'd implemented the rust solutions for those days, I
couldn't be bothered to rewrite the linear algebra code for day 24, or the graph
traversal for day 25.
I did not impose any restrictions on external libraries in rust, as most of the ones I would pull in are already written in rust, so are a fair representation of the performance of the language.
Safety and stability
For rust, I limit myself to no unsafe usage and no nightly features. I also
attempt to not use unwrap/expect unless I can demonstrate that it's safe to do
so. The benchmarks for rust were compiled without cpu-native, for portability
reasons.
Algorithm differences
For the most part, the overall algorithms are identical between the rust and python implementations. There are occasional differences in optimizations where permitted by the language: many of the bitmap tricks are more effective in rust, for example.
Musings
I won't go into too much detail on the specifics of the rust optimizations.
There are other
posts
for that. The general things apply, like using FxHash instead of the default
hashing algorithm, Vec in place of hashing in general, if possible, and
bitmaps whenever convenient. Generally, rust is fast enough that even
sub-optimal algorithms will run in reasonable times. Most of the performance
gains are in data structure choices and avoiding unnecessary allocations. Easy
parallel processing with rayon is icing on the cake.
There are much better resources than me for this stuff.
Python performance "surprises"
The python optimizations are much more interesting, mostly because of how much less fun they were to implement. In my experience this year, the biggest influence on python performance is leveraging the parts of the python standard library that wrap C structures and functions. This often means a sub-optimal algorithm will yield better results because it's able to leverage some C function.
Take str.replace(...), for instance. Despite needing to allocate memory to
hold the new string, this is significantly faster than scanning the string with
a python loop.
Here's a snippet from the solution for day 2, where replacing all the keys in the entire input string is faster than parsing those out in python:
# yeah, so because the replaces are in C, we can use this sequence
# to shrink the size of the input so that the splits have less work and
# require less space for allocations. Note the order of the replaces.
for line in input.replace('green', 'g').replace('blue', 'b').replace('red', 'r').replace(";", ",").replace("Game ", "").splitlines():
parts = line.split(": ", 1)
id = int(parts[0])
# ...
And from day 5 where replacing "seeds: " with " " is faster than splitting
the string again (this one also has the list(map(int, ...)) pattern that is
noticeably faster than aggregating with a for loop).
groups = input.split("\n\n")
self.seeds = list(map(int, groups[0].strip().replace("seeds: ", "").split()))
For large if-else or match blocks, it was sometimes easier to look up the
condition from a dictionary, because the cost of the hashing operation for the
lookup was lower than the cost of evaluating the various conditions.
Check out this abomination from day 1:
STARTING = {
'o': one,
't': two_three,
'f': four_five,
's': six_seven,
'e': eight,
'n': nine,
# this is slightly faster than checking isdigit() then parsing to int()
'0': lambda _a, _b: 0,
'1': lambda _a, _b: 1,
'2': lambda _a, _b: 2,
'3': lambda _a, _b: 3,
'4': lambda _a, _b: 4,
'5': lambda _a, _b: 5,
'6': lambda _a, _b: 6,
'7': lambda _a, _b: 7,
'8': lambda _a, _b: 8,
'9': lambda _a, _b: 9,
}
def match_line(idx: int, line: str):
first = line[idx]
if first in STARTING:
return STARTING[first](idx + 1, line)
else:
return None
These sorts of things have an impact on readability/clarity. For instance, passing tuples and accessing their values is faster than defining a struct-like class to organize data. This results in lines like this one from day 19 which specifies a queue of a tuple consisting of tuples representing ranges (plus some other state data):
intervals = deque()
intervals.append(((1, 4000), (1, 4000), (1, 4000), (1, 4000), "in", 0))
total = 0
# ...
This results in some hard-to-follow manipulations later because we have to remember what the indexes mean, though it is faster than wrapping the data in something that has named attributes:
x, m, a, s, wf, rule_idx = intervals.pop()
if wf == 'A':
total += (x[1] - x[0] + 1) * (m[1] - m[0] + 1) * (a[1] - a[0] + 1) * (s[1] - s[0] + 1)
Compare this to the rust implementation where we have an IntervalSet struct
(which itself, holds four intervals), as well as a clear type definition for the
intervals queue.
// interval set
#[derive(Debug, Clone, Copy, PartialEq, Eq, PartialOrd, Ord, Hash)]
pub struct IntervalSet {
x: Interval<i64>,
m: Interval<i64>,
a: Interval<i64>,
s: Interval<i64>,
}
// ...
let mut intervals: Vec<(IntervalSet, Decision, usize)> =
vec![(IntervalSet::default(), Decision::Workflow(in_workflow), 0)];
Similarly, grid structures in python were usually best left as strings, as the
extra time it would take to process them outweighed the potential speedup in
storing them as a different structure. That and python already allows for
relatively fast iteration through strings. This had downsides in translating
solutions from rust to python, as cardinal neighbor iteration had to be
re-implemented instead of just relying on my Grid type's
cardinal_neighbors(...) function in my rust helper library.
On the topic of libraries, because of the python import mechanism, the time
added by an import statement had to be weighed against the benefit that import
provided. For day 24, when I got lazy and just imported numpy for the linalg
functions, the numpy import added an additional 100 ms to the cold-start time
and first-run application benchmarks. I did end up switching to sympy because
of `numpy precision issues, which helped the cold-start time slightly. In a way,
my desire to avoid external libraries ended up saving me runtime, even if it
cost me time in implementing specific things.
It was "easy" to translate my python solutions into rust. I don't know if it would have been as easy to go the other way without the compiler to hold my hand and make sure I wasn't making dumb mistakes like passing an argument in the wrong position. Overall, clear abstractions have little, if any overhead in rust, while potentially having a lot in python.
Multiprocessing
In rust with rayon, processing iterators/collections in parallel is relatively
simple, as long as you don't need mutable references during the processing
steps. There is a bit of overhead in setting up the work-stealing pool that
rayon uses, so it ends up not being worth it for solutions that already yield a
result in 200 or so microseconds.
Because python threads are still bound by the GIL, we often turn to the
multiprocessing module to spawn separate python processes to do work in
parallel. This module has an even higher cost than rayon, as this starts new
instances of the python interpreter, and communication between processes is done
by serializing objects and state from the parent process to the spawned process.
This means that iterating through a work queue with something like pool.map
can be very expensive if the arguments to the mapped function contain large
objects or many argument. This cost starts to become worth it around the 300
millisecond mark in python (on my system).
Some things that improved multiprocessing runtimes slightly were using the
initializer argument to multiprocessing.Pool to copy over complex state that
would be the same on each worker process (graphs, grids, other immutable
datastructures). This has the benefit of both cutting down the number of
arguments that would need to be serialized during a pool.map, and also
reducing the overall size of the data that would need to be passed between
processes. Leveraging this technique allows for bringing the runtime of day 23
to under 350 ms without making assumptions about the absolute shape of the
graph.
def pool_init(s, g):
global sloped
global graph
sloped = s
graph = g
# in solver body
with Pool(initializer=pool_init, initargs=[slope_graph, graph]) as pool:
# ...
# in dfs step in a pool.map
def dfs(start, cur_cost, goal, seen, ls) -> int:
global graph
longest = [0]
longest_recur(start, cur_cost, goal, graph, ls, seen, longest)
return longest[0]
This does make things a little trickier to follow, as the source of data stored in global variables isn't always immediately clear without finding the location in code that set it.
Cold-starts
In addition to application benchmarks, I've also measured cold-start times.
For my purposes, the cold-start time is the entire time it takes to start and
execute a solution for a given day and input. In the case of python, this time
includes the time it takes for the interpreter to start. We can measure these
times with hyperfine, which also
provides a language-agnostic means of comparing solutions. I measured my
cold-starts on a Beelink SER6 Pro with a Ryzen 7 7735HS and 32 GB of RAM with
the stock, mediocre NVMe drive. The cold-starts being measured on a different
system is mainly a byproduct of my CI setup. The node I develop on is a little
too noisy for this because it's also my primary kubernetes node. The P/E cores
also have an impact on shell start times, which throws off the hyperfine
measurements.
The total cold-start time for rust is sitting around 56.7 ms, with python coming in at 2.2 seconds. Most of slowdown is due to the 7735HS being less capable than my i5-12600k, though, we also have to factor in the overhead of IO and things like the interpreter starting.
Because of how the cold-start is measured - a shell is spawned to execute the
desired command - there is a good amount of variance when dealing with times
less than 5 ms, as hyperfine attempts to compensate for the shell startup
overhead by subtracting the average shell startup time from the warmup period.
While there is the option to run without a shell, this makes the invocation
less general when dealing with solutions in languages that require a shell
environment to run.
Below is a comparison between rust and python made using hyperfine (note the
log-scaled y-axis so the rust solutions wouldn't appear as tiny slivers at the
bottom of the chart):
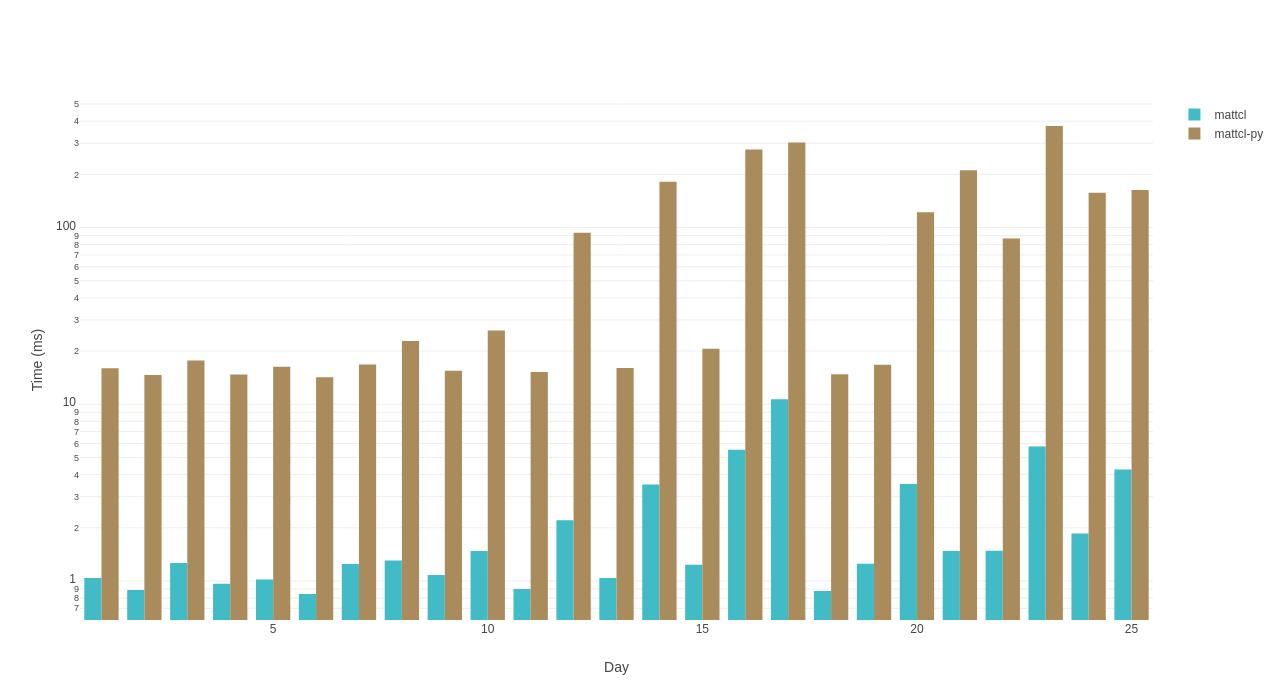
log-scale cold-start comparison between rust and python
What we can see from this is the 14 ms "wall" that is the python interpreter startup time on that particular machine. If running solutions day by day, this overhead adds roughly 350 ms to the aggregated cold-start runtimes.
A more interesting chart is looking at the overall cold-start runtime-percentage-by-day between the two:
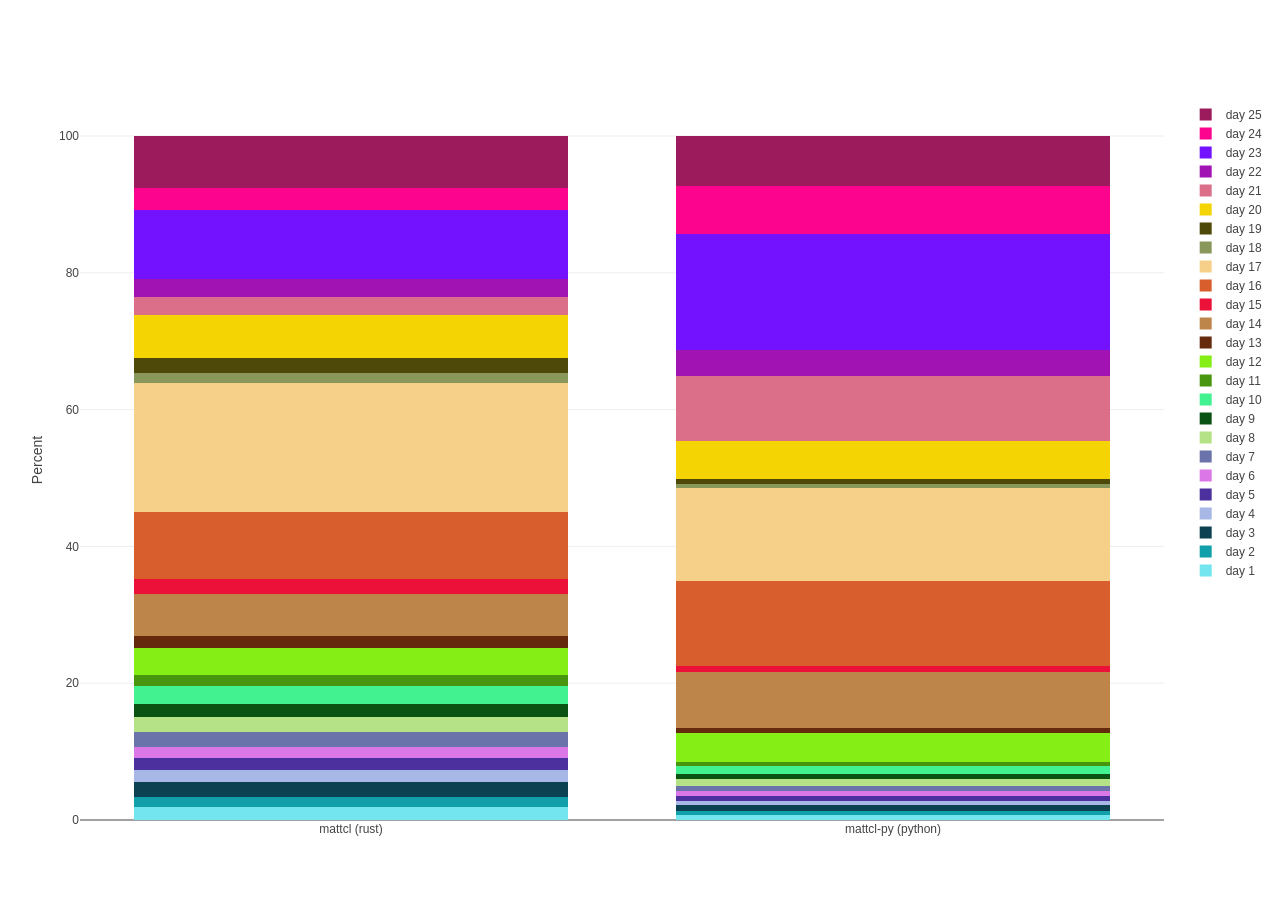
percent of overall runtime between rust and python
What's encouraging here is that the percentage breakdowns are roughly in the same ballpark, with day 23's difference probably attributed to just how inefficient multiprocessing is compared to "real" threads.
Conclusions
As I was working on both implementations (rust first, then python), it became
painfully obvious that I was sacrificing python readability in the quest for
speed. Granted, if I was working on any other project and required speed, python
would not be my first choice, so it's unfair to call this a fault of the
language. Python doesn't necessarily advertise itself as fast. If you were
trying to write the fastest python you could (without just calling out to an
external compiled library like polars or numpy), that speed would very
likely come at the cost of long-term maintainability/readability. The best way
to avoid that would seem to be very explicit variable names when destructuring
arrays/tuples, though those destructures have a cost in terms of copies in some
instances, so it's sometimes better to leave the tuple intact.
On the other hand, the compiled nature and other features make the abstracting of data and logic mostly zero-cost in rust, meaning that you can "have your cake and eat it" when it comes to being clear about what you're doing and why, while not taking a performance hit. As I was refactoring my rust solutions based on techniques/algorithms from other solutions I've looked at, the compiler and type system did a great job at letting me know if I'd broken something and, if I needed to change something, every location that needed to change.
I don't think this experiment really says anything anyone didn't already know, but, for me, optimizing my rust solutions was an exercise in devising a better algorithm and implementing that in rust. My python optimizations were taking an algorithm and trying to exploit the parts of the python standard library that would let me execute that algorithm faster, sometimes taking an O(n^2) approach because the functions that made it O(n^2) were written in C and would be faster.
I'm still a little upset about that str.replace(...) thing.